
Data Annotation- Stepping stone to the technical era
What is data annotation?
Data annotation also know as data labelling plays an essential role in guaranteeing your artificial intelligence and ML projects are trained with the right information to learn. Data annotation and labelling provide the primary setup for satisfying a machine learning model with what it needs to recognize and discriminate against multiple inputs to come up with concrete outputs. By regularly feeding tagged and annotated datasets via an algorithm, you are in a position to set up a dummy that can start getting smarter over time. The more incredible annotated information you use to educate the model, the smarter it becomes. But you cannot do it without a little help. Producing the fundamental annotation from the asset at scale is a task for many. It is mostly due to the complexity concerned with annotation. Getting the most accurate labels needs time and expertise.
Data annotation in machine learning?
Data annotation is the manner of including metadata to a dataset. This metadata generally takes the shape of tags, which get delivered to any data, together with text, images, and video. Adding comprehensive and consistent tags is a vital part of developing a training dataset for machine learning.
Data annotation is a crucial stage of data preprocessing because supervised machine learning models examine to understand recurring patterns in annotated data. After an algorithm has processed adequate annotated data, it can begin to apprehend the identical patterns when introduced with new, unannotated data. As a result, information scientists want to use clean, annotated information to instruct machine learning models.
List down the data annotation types?
There are many distinctive kinds of data annotations, all of which go well with different use cases. In the area below, we run through a few of the other frequent annotation kinds that are used for famous machine learning projects. It’s using no means an exhaustive listing, however, have to supply you some notion of the breadth of the area of data annotation. Let’s dive in:
- Image and Video Annotation
- Text Categorization
- Semantic Annotation
- Entity Annotation
- Intent Extraction
- Phrase Chunking
What is the use of data labelling?
Data labelling is an essential phase of statistics preprocessing for ML, especially for supervised learning, in which both input and output records are labelled for classification to furnish a learning foundation for future statistics.
A machine training to discover animals in images, for example, maybe furnished with a couple of pictures of various types of animals from which it would research the trendy aspects of each, enabling it to discover the animals in unlabeled images correctly.
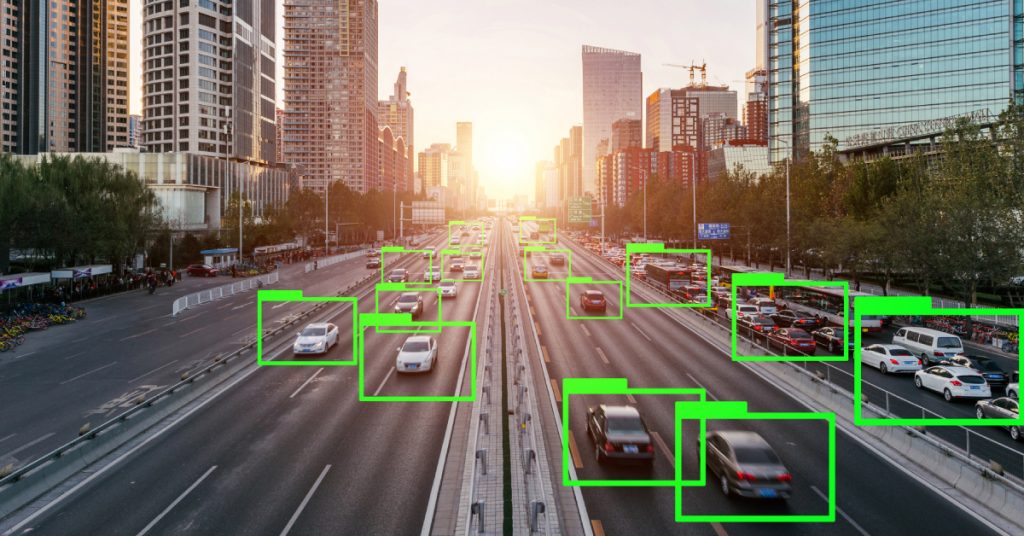
Data labelling, additionally used when developing ML algorithms for independent vehicles. Autonomous automobiles such as self-driving vehicles want to be able to inform the distinction between objects in their path so that they can process the exterior world and drive safely. Data labelling is used to allow the car’s artificial intelligence (AI) to inform the distinction between a person, the street, any other vehicle, and the sky via labelling the fundamental points of these objects or data points and searching for similarities between them.
Importance of data labelling
The latest document from AI research and advisory company Cognilytica discovered that over 80% of the time organizations spend on AI tasks go towards preparing, cleaning, and labelling data. Manual data labelling is the most time-consuming and high priced method; however, it can also get warranted for necessary credentials.
Critics of AI speculate that automation will put low skill-jobs such as call centre work, truck, and Uber driving at hazard because rote duties are turning into more uncomplicated to function for machines. However, some professional agree with that information labelling may present a new low-skill job probability to substitute the ones that are nullified with the aid of automation. It is due to the fact there is an ever-growing surplus of statistics and machines that need to process it to operate the duties vital for superior ML and AI.
Conclusion
Feel free to contact us for our services and to get more details. As technology is moving fast, we will have to keep up with it; thus, we will reach higher and higher.



{kind=link}
{kind=link}
{kind=link}